






Welcome to the world of Machine Learning in Data Science!
In this blog, we will explore the exciting intersection of these two fields, diving into the role of machine learning in data science, understanding its applications and challenges, and getting to know the fundamental algorithms used to extract insights and knowledge from data.
From real-time navigation, image recognition, product recommendation, and speech recognition to fraud detection and online recommendation engines, we will discover how machine learning is used to make sense of the data and drive better business outcomes.
With an engaging and friendly tone, we will also compare Data Science and Machine Learning and answer some of the frequently asked questions. So, fasten your seatbelt and prepare to embark on an insightful journey into Machine Learning in Data Science!
What is Data Science?

Data science is an interdisciplinary field that uses statistical, computational, and machine-learning techniques to extract insights and knowledge from data. It uses data, statistical algorithms, and systems to extract knowledge and insights from structured and unstructured data.
What is Machine Learning?

Machine learning is teaching computers to learn from data without being explicitly programmed. It involves training a model on a dataset, allowing it to make predictions or take actions in unseen situations. It is a subset of Artificial Intelligence that automatically enables systems to improve from experience.
Why is Machine Learning Important?
- Predictive Capabilities: Machine learning allows for the development of models that make predictions based on input data, which is used to make better decisions and optimise processes.
- Automation: Machine learning algorithms can automate repetitive tasks, such as data analysis and prediction, which can save time and improve efficiency.
- Handling Complex Data: Machine learning can be used to process and analyze large and complex datasets that would be difficult for humans to handle manually.
- Continuous Improvement: Machine learning models can improve over time as they learn from new data, leading to more accurate predictions and better performance.
The Role of Machine Learning in Data Science
Machine learning plays a crucial role in data science and is responsible for much of the recent progress in the field. At its core, data science is all about using data to understand the world around us and make better decisions.
Machine learning is a powerful tool that enables us to do just that by allowing us to train models that can automatically extract insights and predictions from large and complex data sets.
The role of machine learning in data science is divided into three main areas: data preparation, model training, and model deployment. In data preparation, machine learning algorithms are used to clean and preprocess data so that it is used for analysis.
This module includes missing value imputation, outlier detection, and feature extraction.
Once the data is prepared, the next step is to train a model on it. This is where the core of machine learning comes in, as various algorithms, such as linear and logistic regression, Random Forest, SVM, Naive Bayes, Neural Networks, etc., are used to learn from the data and make predictions or take actions.
These models can be supervised, unsupervised, or semi-supervised, depending on the problem's nature and the availability of the labelled data.
Finally, the last step is model deployment, which uses the trained model to predict or take actions in a real-world setting. These trained model actions can include classification, regression, anomaly detection, and natural language processing.
Machine learning has a wide range of applications in data science, including but not limited to predictive analytics, computer vision, natural language processing, and recommendation systems.
These applications are crucial for industry and have been used to solve various problems, from improving customer service to detecting fraud, from medical diagnosis to self-driving cars.
What are the Applications of Machine Learning in Data Science?

1) Real-Time Navigation
Real-time navigation is one of the most popular applications of machine learning in data science. It uses machine learning algorithms to analyse data from sensors and cameras, such as GPS, LiDAR, and cameras, to provide users with real-time navigation guidance.
One of the key challenges in real-time navigation is dealing with the vast amount of data generated by sensors and cameras. Machine learning algorithms are used to process this data and extract useful information, such as the location and speed of vehicles, the location of obstacles, and the flow of traffic.
This information is then used to provide real-time guidance to users, such as turn-by-turn directions, traffic alerts, and real-time traffic updates.
These days, machine learning techniques are used to enhance the precision and dependability of real-time navigation for autonomous cars. Machine learning algorithms are used to evaluate data from various sensors, including cameras, LiDAR, and radar, to grasp the environment around the vehicle.
The capacity of these algorithms to predict the behaviour of other cars, pedestrians, and bicycles on the road is critical to the safe mobility of autonomous vehicles.
2) Image Recognition
Image recognition is another popular application of machine learning in data science. It uses machine learning algorithms to analyse and understand images, such as photographs, videos, and live streams.
Image recognition aims to teach machines to identify and understand the objects, people, and scenes within images and to extract useful information from them.
One of the key challenges in image recognition is the vast amount of data generated by images. Machine learning algorithms are used to process this data and extract useful information, such as the objects and people within an idea and the scene or context in which they are located.
This information can be used for various tasks, such as image search, object detection, and image captioning.
One of the most popular approaches to image recognition is convolutional neural networks (CNNs). CNNs are a deep learning algorithm designed to process image data and extract features.
They work by analysing an image at multiple scales and extracting features at different levels of abstraction, such as edges, shapes, and textures. These features are then used to classify the image or extract useful information.
3) Product Recommendation
Product recommendation is another popular application of machine learning in data science. It involves using machine learning algorithms to analyse data about customers and products to make personalised recommendations to customers.
Product recommendation aims to improve the customer experience by providing recommendations for products they are more likely to be interested in.
One of the key challenges in product recommendation is dealing with the vast amount of data that customers and products generate. Machine learning algorithms process this data and extract useful information, such as customer preferences, purchase history, and development features.
This information is then used to make personalized recommendations to customers.
One of the most popular approaches to product recommendation is the use of collaborative filtering. Collaborative filtering is a technique that uses the past behaviour of customers, such as their purchase history, to make recommendations to other customers who have similar behaviour.
For example, if two customers have identical histories, then the products one customer has bought in the past may be recommended to the other customer.
The application of content-based filtering is an additional well-liked strategy. The characteristics of items, such as their category, brand, and price, are used in content-based filtering to provide suggestions.
For instance, if a consumer purchases a product from a particular brand, the customer may be recommended additional goods.
Product recommendations are connected to several platforms in recent years, including social networking platforms, streaming services, and e-commerce websites.
Online streaming platforms use product recommendations to suggest similar content to viewers, e-commerce websites use product recommendations to show personalised product recommendations to customers on their homepage or product pages, and social media platforms use product recommendations to suggest pages or groups to users based on their interests.
4) Speech Recognition
Speech recognition is another popular application of machine learning in data science. It involves using machine learning algorithms to analyse speech to convert it into text or other forms of data.
The goal of speech recognition is to enable machines to understand and interpret human speech so that it can be used for various tasks, such as voice commands, transcription, and language translation.
One of the critical challenges in speech recognition is dealing with the vast amount of speech-generated data. Machine learning algorithms process this data and extract useful information, such as spoken words and phrases and the speaker's intent.
This information is then used to convert speech into text or other forms of data, such as commands or questions.
One of the most famous speech recognition approaches is using neural networks. Neural networks are machine learning algorithms designed to process large amounts of data and extract features.
They work by analysing speech at multiple levels, such as the phonemes and the intonation, and removing elements such as the rhythm, pitch, and the speaker's voice.
Another popular approach is the use of phoneme-based models. Phoneme-based models are based on the idea that speech can be broken down into a sequence of phonemes (the smallest unit of speech that can carry a distinct meaning).
These models use machine learning algorithms to learn the patterns between the phonemes and the corresponding words or sentences.
What are the Challenges of Machine Learning in Data Science?

1) Lack of Training Data
One of the biggest challenges of machine learning in data science is the need for more training data. Machine learning models require large amounts of data to learn and make accurate predictions. However, in many cases, the available data is limited, making it challenging to train effective models.
Several factors, such as data privacy concerns, data collection limitations, and data labelling challenges, can cause the lack of training data. Data privacy concerns can make it difficult to acquire data from specific sources, such as social media or medical records.
Data collection limitations can make it difficult to gather data from specific sources, such as sensors or cameras. Data labelling challenges can make it difficult to label and annotate the data, which is necessary to train some machine learning models.
One of the critical solutions to the need for more training data is synthetic data. Synthetic data is artificially generated data that can supplement or replace accurate data. This can be done using generative models, such as GANs, or data augmentation techniques, such as adding noise or rotation to images.
Another solution is transfer learning, where a model trained on a related task or dataset can be fine-tuned on a smaller dataset.
2) Discrepancies between Data
Another challenge of machine learning in data science is discrepancies between data. The data used to train and test machine learning models can vary significantly in terms of quality, format, and relevance. This can make it challenging to train accurate and reliable models and lead to biased or inconsistent results.
Several factors, such as data collection methods, data cleaning techniques, and annotation processes, can cause discrepancies between data. Data gathering methods, such as sensor kinds or data collection durations, might result in data disparities.
Data cleaning strategies, such as missing value imputation or outlier identification, might result in discrepancies. Data annotation methods, such as how data is labelled or annotated, might cause changes in the data.
Data standardisation is an effective tactic for addressing data problems. Data standardisation includes making the data consistent and comparable by converting it into a uniform format or deleting extraneous or inconsistent material.
This may be accomplished using data cleaning techniques like missing value imputation or outlier identification and normalising data techniques like min-max scaling or z-score normalisation.
Data integration, which is the process of merging data from many sources, is another option. Data warehousing and data federation are two examples of data integration approaches that may be used to do this. Data integration technologies, such as platforms and software, can also accomplish this.
3) Model Scalability
Another challenge of machine learning in data science is model scalability. Machine learning models can be computationally expensive and may need help to handle large amounts of data or make predictions in real time.
It can be challenging to deploy machine learning models in large-scale systems, such as online platforms, IoT devices, or autonomous systems.
Model scalability can be affected by several factors, such as the model's complexity, the data's size, and the computational resources available. Complex models, such as deep neural networks, can require large amounts of memory and processing power and may not be able to handle large amounts of data.
Large datasets can also require large amounts of memory and processing power and may not be able to be processed in real-time.
One of the key solutions to model scalability is model compression. Model compression involves reducing the size and complexity of a model without sacrificing its accuracy.
It can be done using pruning, quantisation, and low-rank factorisation techniques. These techniques can reduce the size of a model and make it more computationally efficient.
Another solution is distributed learning, training a model using multiple machines or devices. It can be done using data parallelism, model parallelism, or federated learning. These techniques can speed up the training process and make it more computationally efficient.
What is the Role of Machine Learning in Data Science?
Machine learning is a rapidly growing field that plays a critical role in data science. It is a branch of artificial intelligence that enables computers to learn from data and make predictions or take actions. Machine learning is used to extract insights and predictions from data and to use them to make decisions or take action.
Machine learning comes in various forms: reinforcement, unsupervised, and supervised learning. A model is trained using labeled data, such as data that has been classed or marked, through supervised learning. Making predictions or taking actions based on new data is the aim of supervised learning.
Unsupervised learning is developing a model using unlabeled data, such as unclassified or unlabeled data. Unsupervised learning aims to find structures or patterns in the data.
Reinforcement learning is the process of teaching a model to function in a particular environment, such as a game or a robot, using feedback in the form of rewards or penalties.
In business, machine learning is used to analyse customer data and predict customer behaviour, such as customer churn or product recommendations. In healthcare, machine learning analyses medical data and predicts patient outcomes, such as disease progression or treatment effectiveness.
In finance, machine learning is used to analyse market data, predict stock prices, or detect fraudulent transactions.
The role of machine learning in data science is wider than these examples. For instance, In self-driving cars, Machine learning is used to detect objects and predict their movement, making the car drive safer and more efficient. In manufacturing, machine learning is used to predict equipment failures and optimise production processes.
5 Major Steps of Machine Learning in the Data Science Lifecycle
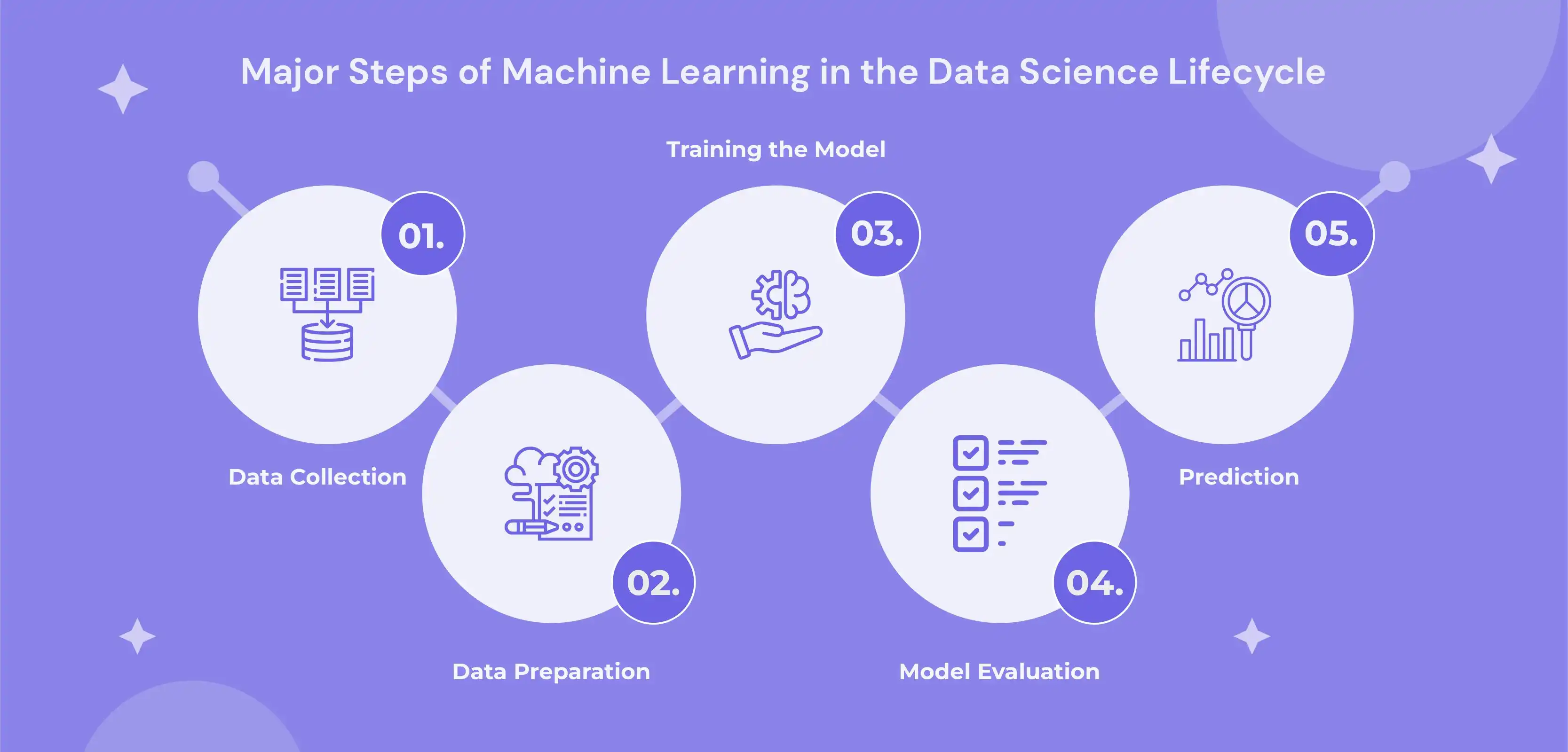
1) Data Collection
Data collection is an essential step in applying machine learning in data science. It involves gathering and acquiring data from various sources, such as databases, social media, sensors, and other digital platforms.
The goal of data collection is to obtain the data needed to train and evaluate machine learning models and extract insights and predictions from them.
One of the key challenges in data collection is dealing with the vast amount of data generated by various sources. Machine learning algorithms process this data and extract useful information, such as customer preferences, purchase history, and product features.
There are several popular approaches to data collection in machine learning, including web scraping, API, and data warehousing. Web scraping involves software or scripts automatically extracting data from websites or other online sources.
API allows the data to be removed from the database or the software. Data warehousing involves storing and accessing data in a central location and accessing it through a query language.
2) Data Preparation
Machine learning in data science involves several key steps, including data preprocessing. It entails preparing the gathered data for analysis by cleaning and prepping it.
Making the data acceptable for use with machine learning algorithms and obtaining insightful conclusions and predictions from it are the two main objectives of data preparation.
Dealing with the enormous volume of data created by diverse sources is one of the main issues in data preparation. The processing of this data by machine learning algorithms yields essential information about customers' preferences, past purchases, and product attributes.
Missing value imputation, outlier identification, and feature extraction are a few common methods used in machine learning for data preparation. Imputation of missing values entails substituting an appropriate value, such as the mean or median of the data, for the missing data.
Finding and eliminating outliers from the data is known as outlier identification. The feature extraction process involves analyzing-useful characteristics from the data, such as the mean, median, and standard deviation.
3) Training the Model
Training the model is important in applying machine learning in data science. It involves using machine learning algorithms to learn from the collected and prepared data to make predictions or take action.
The goal of training the model is to build a model that can generalise well to new data and extract valuable insights and predictions from it.
One of the key challenges in training the model is dealing with the vast amount of data generated by various sources. Machine learning algorithms process this data and extract useful information, such as customer preferences, purchase history, and product features.
In machine learning, there are various well-liked methods for training the model, including supervised, unsupervised, and semi-supervised learning. A model is trained using labelled data, such as data that has been classed or marked, through supervised learning.
Unsupervised learning is developing a model using unlabeled data, such as unclassified or unlabeled data. Semi-supervised education includes training the model on a sizeable amount of unlabeled data and a small amount of labelled data, combining supervised and unsupervised learning.
4) Model Evaluation
Model evaluation is an essential step in applying machine learning in data science. It involves evaluating the performance of a machine learning model to determine its accuracy, reliability, and generalisation. The goal of model evaluation is to select the best model for a given task and to extract valuable insights and predictions from it.
One of the critical challenges in model evaluation is dealing with the vast amount of data generated by various sources. Machine learning algorithms process this data and extract useful information, such as customer preferences, purchase history, and product features.
There are several popular approaches to model evaluation in machine learning, including the holdout method, k-fold cross-validation, and bootstrapping. The holdout method involves splitting the data into a training and a testing set and evaluating the model using the testing set.
K-fold cross-validation consists in dividing the data into k folds, training the model on k-1 folds, and considering the model using the remaining fold. Bootstrapping involves randomly sampling the data with replacement and evaluating the model using the sampled data.
In recent years, model evaluation has been used in various applications, such as natural language processing, computer vision, and anomaly detection. For example, natural language processing uses model evaluation to evaluate the performance of machine learning models on text data, such as accuracy, precision, and recall.
Computer vision uses model evaluation to assess the performance of machine learning models on image and video data, such as object detection and image classification.
5) Prediction
Prediction is an essential step in applying machine learning in data science. It involves using a trained machine learning model to make predictions or actions based on new data. The goal of prediction is to extract insights and predictions from the data and to use them to make decisions or to take action.
One of the critical challenges in prediction is dealing with the vast amount of data generated by various sources. Machine learning algorithms process this data and extract useful information, such as customer preferences, purchase history, and product features.
Regression, classification, and clustering are three widely used methods for prediction in machine learning. Regression entails making predictions about a continuous value, such as the stock market's price or a sensor's temperature.
Clustering combines identical data pieces, such as consumers based on their past purchases or photographs based on their content.
3 Key Machine Learning Algorithms in Data Science
1) Regression
Regression is one of the vital machine-learning algorithms used in data science. It is a supervised learning technique used to predict a constant value, such as a price, a temperature, or a weight. Regression models are used in various applications, such as predicting stock prices, analysing customer data, and modelling climate patterns.
There are several types of regression models, including linear regression, polynomial regression, and logistic regression. Linear regression is the most basic model used to model a linear relationship between a dependent variable and one or more independent variables.
Polynomial regression is an extension of linear regression and is used to model a non-linear relationship between a dependent variable and one or more independent variables. Logistic regression is a type of regression model used to model a binary outcome, such as a yes/no or a true/false.
One of the critical advantages of regression models is their simplicity. Regression models are relatively easy to understand and interpret and can be used to make highly accurate predictions. Additionally, regression models are relatively easy to implement and can be used to analyse large amounts of data.
Another advantage of regression models is their flexibility. Regression models can model many linear, non-linear, and binary relationships. Regression models can also analyse various data types, including numerical, categorical, and text data.
2) Classification
Classification is another critical machine learning algorithm used in data science. It is a supervised learning technique to predict an absolute value, such as a class, category, or label. Classification models are used in various applications, such as image classification, text classification, and speech recognition.
Several classification models include decision trees, random forests, and support vector machines. Decision trees are a classification model that uses a tree-like structure to model decisions and their possible consequences.
Random forests are an extension of decision trees and are used to improve the accuracy and stability of decision trees by averaging the predictions of multiple decision trees. Support vector machines are a classification model that uses a hyperplane to separate different data classes.
One of the critical advantages of classification models is their ability to handle categorical data. Classification models are designed to work with categorical data and can be used to classify data into different categories or classes.
Additionally, classification models can analyse large amounts of data and effectively handle missing and outliers.
3) Clustering
Clustering is a third key machine learning algorithm used in data science. It is an unsupervised learning technique that groups similar data points. Clustering models are used in various applications, such as market segmentation, customer segmentation, and anomaly detection.
There are several clustering models, including k-means, hierarchical clustering, and density-based clustering. K-means is a clustering model that groups data points into k clusters, where k is the number of sets.
Hierarchical clustering is a type of clustering model that groups data points into a hierarchical tree of locations. Density-based clustering is a type of clustering model that groups data points into clusters based on the density of data points.
One of the critical advantages of clustering models is their ability to discover hidden patterns in the data. Clustering models can find ways in the data that would not be visible by other methods, such as linear regression or decision trees.
Additionally, clustering models can analyse large amounts of data and effectively handle missing and outliers.
3 Machine Learning Use Cases in Data Science
1) Fraud Detection
Fraud detection is one of the critical use cases of machine learning in data science. Fraud is any illegal or unethical activity intended to deceive or cheat an individual or an organisation. Fraud can take many forms, such as credit card fraud, insurance fraud, or financial fraud.
Fraud detection identifies and prevents fraudulent activities by analysing data and detecting abnormal behaviour patterns.
Machine learning is used to analyse data and detect patterns of fraudulent behaviour. Several types of machine learning algorithms can be used for fraud detection, such as supervised learning, unsupervised learning, and anomaly detection.
Based on labelled data, supervised learning algorithms, such as decision trees and random forests, classify transactions as fraudulent or non-fraudulent. Unsupervised learning algorithms, such as clustering and association rule mining, are used to discover abnormal behaviour patterns in unlabeled data.
Anomaly detection algorithms, such as one-class SVM and isolation forest, identify instances that deviate from normal behaviour.
One of the key advantages of using machine learning for fraud detection is its ability to handle large amounts of data and detect abnormal behaviour patterns that would not be visible by other methods. Machine learning can also analyse various data types, including numerical, categorical, and text data.
2) Speech Recognition
Speech recognition is another critical use case of machine learning in data science. Speech recognition converts spoken language into text by analysing the audio signal and identifying spoken words. It is used in various applications, such as voice assistants, dictation software, and call centres.
The audio stream is analysed using machine learning, recognising spoken words. Machine learning techniques can be utilised for voice recognition, including supervised, unsupervised, and deep learning.
Speech sounds are categorised into phonemes, which are the fundamental building blocks of speech, using supervised learning methods like hidden Markov models. Unsupervised learning methods like k-means and hierarchical clustering are employed to find patterns in the audio input.
Convolutional neural and recurrent neural networks are two examples of deep learning techniques that simulate the intricate connections between spoken words and audio input.
The capacity of machine learning to handle enormous volumes of data and adapt to varied accents and languages is one of the main benefits of utilising it for voice recognition. Additionally, various data kinds, including audio, text, and picture data, may be analysed using machine learning.
3) Online Recommendation Engines
Online recommendation engines are the third critical use case of machine learning in data science. Based on their previous interactions and behaviours, recommendation engines predict what users might be interested in. They are used in various applications, such as e-commerce, online streaming, and social media.
By examining user interactions and habits, machine learning can forecast what they might be interested in. Recommendation engines can employ various machine-learning techniques, including collaborative, content-based, and hybrid filtering.
Using the commonalities between users to forecast what they would be interested in, collaborative filtering is a method that is based on prior user activity. Using the similarities between objects, content-based filtering, a technique based on the features of things, may forecast what a user would be interested in.
To provide more precise predictions, an approach called hybrid filtering combines both collaborative filtering and content-based filtering.
The capacity to tailor the user experience is one of the main benefits of employing machine learning for online recommendation engines. It is possible to utilise recommendation engines to suggest goods, media, or other things most likely to interest the user.
Additionally, various data kinds, including numerical, category, and text data, may be analysed using machine learning.
The capacity of machine learning to get better over time is another benefit of employing it for online recommendation engines. Programming machine learning algorithms on new data may enhance their performance and accuracy.
Conclusion
In summary, machine learning is a potent tool in the Data Science space. We may use it to create predictions and judgments, extract insights and information from data, and find hidden patterns that would not be obvious using other techniques.
As we've seen, machine learning is crucial to various applications, including fraud detection, real-time navigation, picture identification, and product recommendations.
However, machine learning also comes with its share of difficulties, including a need for more training data, conflicts between data, and model scalability. Effective data collection, preparation, model training, assessment, and prediction procedures are necessary to make the most of the data.
It is also crucial to remember that Machine Learning is a particular method applied within the broader subject of Data Science. Data science is utilised in various industries, including healthcare, banking, and retail.
It involves different techniques, including data visualisation, statistical modeling, and machine learning. It is a multidisciplinary subject that combines domain knowledge, statistics, and computer science to draw conclusions and information from data.
drives valuable insights
Organize your big data operations with a free forever plan
An agentic platform revolutionizing workflow management and automation through AI-driven solutions. It enables seamless tool integration, real-time decision-making, and enhanced productivity
Here’s what we do in the meeting:
- Experience Boltic's features firsthand.
- Learn how to automate your data workflows.
- Get answers to your specific questions.



